虚拟地址和物理地址
计算机中虚拟地址与物理地址
一、了解基本概念
1.地址空间
我们最开始接触地址的时候,应该是在我们学习数组的时候。地址空间其实是一个比较抽象的概念,我们可以把它想象成一个长的数组,每个数组元素占一个字节。那么这个数组的长度就由地址空间长度来决定。例如:我们32位的系统的地址空间就是我们的$2^{32}$字节(4GB),而64位的地址空间大小就是$2^{64}$个字节。这也就解释了在我们32位的操作系统,为什么最大只能支持4GB的有效内存。

2.虚拟地址的由来
在早期的计算机中,程序是直接运行到物理内存(可以理解为内存条上的内存)上的。也就是说,程序运行的时候直接访问的就是物理地址。如果,我们的一个计算机只运行一个程序,那么只有这个程序所需要的内存空间不超过物理内存空间的大小,就不会有问题。但是,我们正在希望的是在某个时候同时运行多个程序。那么这个时候,就会有个一个问题,计算机如何把有限的物理内存分配给多个程序使用呢?
某台计算机总的内存大小是128M,现在同时运行两个程序A和B,A需占用内存10M,B需占用内存110。计算机在给程序分配内存时会采取这样的方法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分出110M分配给程序B。这种分配方法可以保证程序A和程序B都能运行,但是这种简单的内存分配策略问题很多。
问题1:进程地址空间不隔离。由于程序都是直接访问物理内存,所以恶意程序可以随意修改别的进程的内存数据,以达到破坏的目的。有些非恶意的,但是有bug的程序也可能不小心修改了其它程序的内存数据,就会导致其它程序的运行出现异常。这种情况对用户来说是无法容忍的,因为用户希望使用计算机的时候,其中一个任务失败了,至少不能影响其它的任务。
问题2:内存使用效率低。在A和B都运行的情况下,如果用户又运行了程序C,而程序C需要20M大小的内存才能运行,而此时系统只剩下8M的空间可供使用,所以此时系统必须在已运行的程序中选择一个将该程序的数据暂时拷贝到硬盘上,释放出部分空间来供程序C使用,然后再将程序C的数据全部装入内存中运行。可以想象得到,在这个过程中,有大量的数据在装入装出,导致效率十分低下。
问题3:程序运行的地址不确定。当内存中的剩余空间可以满足程序C的要求后,操作系统会在剩余空间中随机分配一段连续的20M大小的空间给程序C使用,因为是随机分配的,所以程序运行的地址是不确定的。但是我们的某些硬件是需要在固定的地址上去开始运行的,但是如果这个地址后边被我们的程序占有,那么我们对这块内存的修改,就可能导致某些硬件不可用了。
为了解决上述问题,人们想到了一种变通的方法,就是增加一个中间层,利用一种间接的地址访问方法访问物理内存。按照这种方法,程序中访问的内存地址不再是实际的物理内存地址,而是一个虚拟地址,然后由操作系统将这个虚拟地址映射到适当的物理内存地址上。这样,只要操作系统处理好虚拟地址到物理内存地址的映射,就可以保证不同的程序最终访问的内存地址位于不同的区域,彼此没有重叠,就可以达到内存地址空间隔离的效果。
二、虚拟地址和物理地址映射
了解了我们的虚拟地址和物理地址的由来,下面我们来总结一下,他们的概念.
物理地址:物理地址空间是实在的存在于计算机中的一个实体,在每一台计算机中保持唯一独立性。我们可以称它为物理内存;如在32位的机器上,物理空间的大小理论上可以达到$2^{32}$字节(4GB),但如果实际装了512的内存,那么其物理地址真正的有效部分只有$512MB = 512 \times 1024 KB = = 512 \times 1024 \times 1024 B (0x00000000\sim0x1fffffff)$。其他部分是无效的。
虚拟地址:虚拟地址并不真实存在于计算机中。每个进程都分配有自己的虚拟空间,而且只能访问自己被分配使用的空间。理论上,虚拟空间受物理内存大小的限制,如给有4GB内存,那么虚拟地址空间的地址范围就应该是$0x00000000\sim0xFFFFFFFF$.每个进程都有自己独立的虚拟地址空间。这样每个进程都能访问自己的地址空间,
这样做到了有效的隔离。
在上面我们提到了合理的内存管理机制。我们这里虚拟地址和物理地址之间的映射是通过MMU(内存管理单元)来完成的。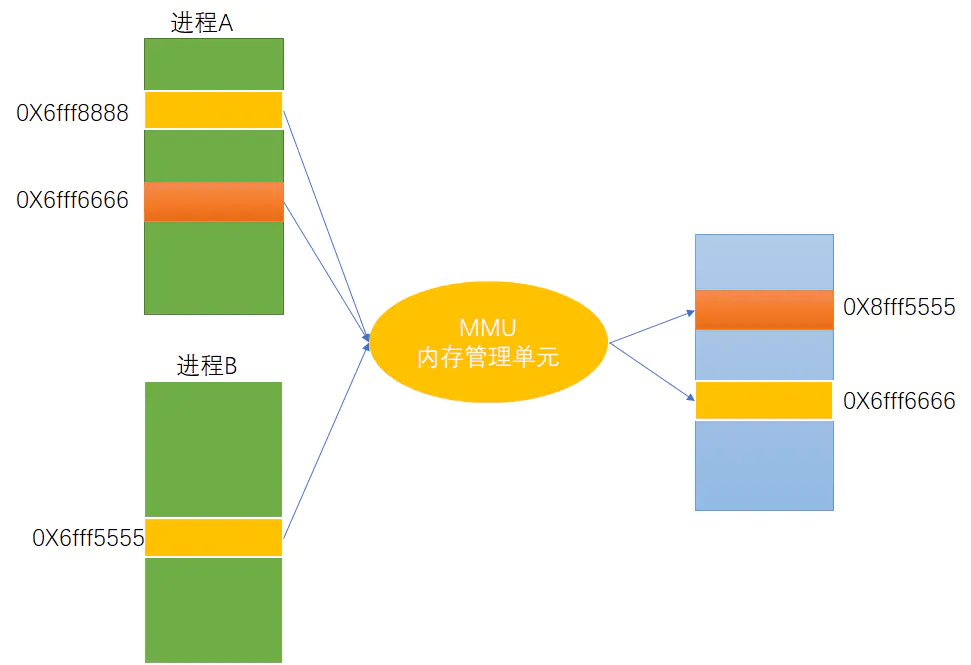
我们平时操作的内存其实都是通过操作虚拟地址的内存单元。通过通过MMU的映射来间接的操作我们的物理地址。
对虚地址的理解
一
- 每个进程都有自己独立的4G内存空间,各个进程的内存空间具有类似的结构。
- 一个新进程建立的时候,将会建立起自己的内存空间,此进程的数据,代码等从磁盘拷贝到自己的进程空间,哪些数据在哪里,都由进程控制表中的task_struct记录,task_struct中记录中一条链表,记录中内存空间的分配情况,哪些地址有数据,哪些地址无数据,哪些可读,哪些可写,都可以通过这个链表记录。
- 每个进程已经分配的内存空间,都与对应的磁盘空间映射。
问题:计算机明明没有那么多内存(n个进程的话就需要$n\times4$G)内存建立一个进程,就要把磁盘上的程序文件拷贝到进程对应的内存中去,对于一个程序对应的多个进程这种情况,浪费内存!
二
- 每个进程的4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址。
- 所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。
- 进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录。
- 页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)。
- 当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常。
- 缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘。
总结
- 既然每个进程的内存空间都是一致而且固定的,所以链接器在链接可执行文件时,可以设定内存地址,而不用去管这些数据最终实际的内存地址,这是有独立内存空间的好处。
- 当不同的进程使用同样的代码时,比如库文件中的代码,物理内存中可以只存储一份这样的代码,不同的进程只需要把自己的虚拟内存映射过去就可以了,节省内存。
- 在程序需要分配连续的内存空间的时候,只需要在虚拟内存空间分配连续空间,而不需要实际物理内存的连续空间,可以利用碎片。
另外,事实上,在每个进程创建加载时,内核只是为进程“创建”了虚拟内存的布局,具体就是初始化进程控制表中内存相关的链表,实际上并不立即就把虚拟内存对应位置的程序数据和代码
(比如.text .data段).拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射),等到运行到对应的程序时,才会通过缺页异常,来拷贝数据。还有进程运行过程中,
要动态分配内存,比如malloc时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!