双向BFS
值得思考的实现
搜索-双向BFS
- 双向bfs适用于知道起点和终点的状态下使用,从起点和终点两个方向开始进行搜索,可以非常大的提高单个bfs的搜索效率。
- 同样,实现也是通过队列的方式,可以设置两个队列,一个队列保存从起点开始搜索的状态,另一个队列用来保存从终点开始搜索的状态,如果某一个状态下出现相交的情况,那么就出现了答案
- 但是双向BFS在针对于小型数据范围时就会退化成BFS,如果双向BFS的两个端点完全没有连接,时间复杂度也会和BFS相同
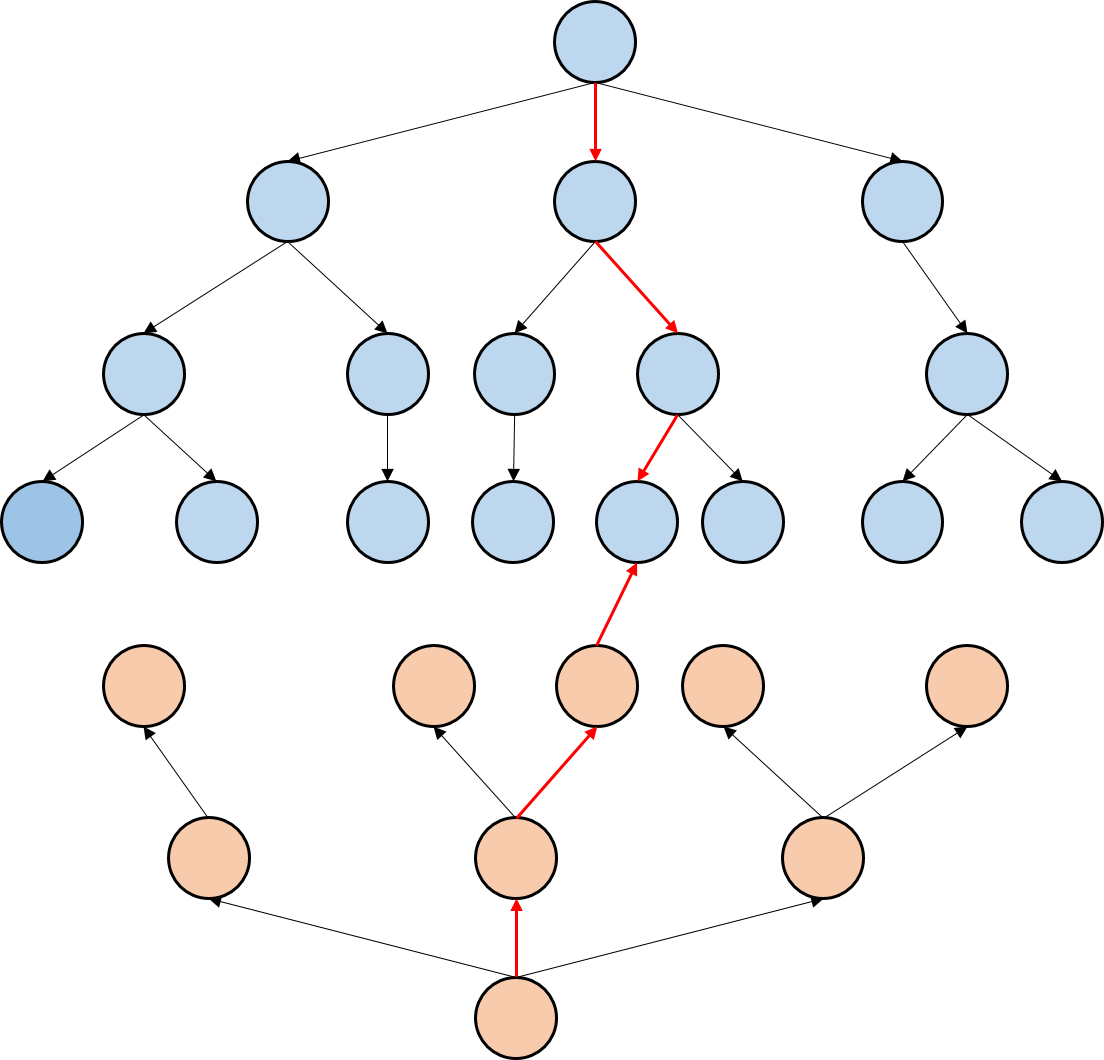
当两种颜色相遇的时候,说明两个方向的搜索树遇到一起,这个时候就搜到了答案。
例题
简单理入门:
问题描述:
一个迷宫由$R$行$C$列格子组成,有的格子里有障碍物,不能走;有的格子是空地,可以走。
给定一个迷宫,求从左上角走到右下角最少需要走多少步(数据保证一定能走到)。只能在水平方向或垂直方向走,不能斜着走。
输入
第一行是两个整数,$R$和$C$,代表迷宫的长和宽。$(1≤R,C≤40)$
接下来是$R$行,每行$C$个字符,代表整个迷宫。
空地格子用‘.’表示,有障碍物的格子用‘#’表示。
迷宫左上角和右下角都是‘.’。
输出
输出从左上角走到右下角至少要经过多少步(即至少要经过多少个空地格子)。计算步数要包括起点和终点
输入样例
5 5
..###
#....
#.#.#
#.#.#
#.#..输出样例
9普通BFS:
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int INF = 100000;
const int MAX = 101;
typedef pair<int, int> P;
char map[MAX][MAX];
int d[MAX][MAX];//表示起点到各个位置的最短距离
int sx, sy, gx, gy;//表示起点和终点坐标
int n, m;
int dx[4] = {1, 0, -1, 0};
int dy[4] = {0, 1, 0,- 1};
bool Check(int x, int y) {
if(x>=0 && x<n && y>=0 && y<m && d[x][y]==INF && map[x][y]!='#')
return true;
else return false;
}
int bfs() {
queue<P> que;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
d[i][j] = INF;
que.push(P(sx, sy));
d[sx][sy] = 0;
while(!que.empty()) {
P p = que.front();
que.pop();
if(p.first == gx && p.second == gy)
break;
for(int i = 0; i < 4; i++) {
int nx = p.first + dx[i];
int ny = p.second + dy[i];
if(Check(nx, ny)) {
que.push(P(nx,ny));
d[nx][ny] = d[p.first][p.second] + 1;
}
}
}
return d[gx][gy];
}
int main() {
cin >> n >> m;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
cin >> map[i][j];
sx = 0, sy = 0;
gx = n-1, gy = m-1;
int res = bfs();
cout << res+1 << endl;
return 0;
}双向BFS:
#include <iostream>
#include <queue>
#define P pair<int, int>
using namespace std;
//记录下当前状态, 从前往后搜索值为1,从后往前搜索值为2,如果某状态下,当前节点和准备扩展节点的状态相加为3,说明相遇
queue <P> q1, q2;
int r, c, ans, dis[45][45], vst[45][45];
int dx[4] = {-1, 0, 1, 0};
int dy[4] = {0, 1, 0, -1};
char m[45][45];
void dbfs() {
bool flag;
q1.push(P(1, 1)), dis[1][1] = 1, vst[1][1] = 1; //从前搜
q2.push(P(r, c)), dis[r][c] = 1, vst[r][c] = 2; //从后搜
while(!q1.empty() && !q2.empty()) {
int x0, y0;
if(q1.size() > q2.size()) { //每次扩展搜索树小的队列 flag=1扩展前搜的队列,flag=0扩展后搜的队列
x0 = q2.front().first, y0 = q2.front().second;
q2.pop();
flag = 0;
}else {
x0 = q1.front().first, y0 = q1.front().second;
q1.pop();
flag = 1;
}
for(int i = 0; i < 4; i++) {
int nx = x0 + dx[i];
int ny = y0 + dy[i];
if(nx >= 1 && nx <= r && ny >= 1 && ny <= c && m[nx][ny] == '.') {
if(!dis[nx][ny]) {
dis[nx][ny] = dis[x0][y0] + 1;
vst[nx][ny] = vst[x0][y0];
if(flag) q1.push(P(nx, ny));
else q2.push(P(nx, ny));
}else {
if(vst[x0][y0] + vst[nx][ny]== 3) { //相遇
ans = dis[nx][ny] + dis[x0][y0];
return;
}
}
}
}
}
}
int main() {
cin >> r >> c;
for(int i = 1; i <= r; i++)
for(int j = 1; j <= c; j++)
cin >> m[i][j];
dbfs();
cout << ans << "\n";
return 0;
}给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回 0。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出: 5
解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度 5。示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: 0
解释: endWord "cog" 不在字典中,所以无法进行转换。如果只是单纯的使用BFS经行操作那么时间复杂度将会为$O(M\times N)$ $M$表示单词的长度, $N$表示单词列表中单词的个数.
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> s; // 可以块数查找
for (auto i : wordList) s.insert(i);
// first 表示字符
// second 表示走过的路长
queue<pair<string, int>> q;
q.push(make_pair(beginWord, 1));
string temp;
int step; // 表示用暂时存贮走过的步子
while (!q.empty()) {
if (q.front().first == endWord) return q.front().second;
temp = q.front().first;
step = q.front().second;
q.pop();
char ch;
for (int i = 0; i <= temp.size(); ++ i) {
ch = temp[i];
for (int a = 'a'; a < 'z'; ++ a) {
if (ch == a) continue;
temp[i] = a;
if (s.find(temp) != s.end()) { // 这里表示如果找到了可以转换的两个单词,就把该数存放入队列里
q.push(make_pair(temp, step + 1));
s.erase(temp); // 删掉结点的意思防止找到重复
}
temp[i] = ch;
}
}
}
return 0;
}如果使用双向BFS:
- $O(M \times N)$,其中 MM 是单词的长度 $N$是单词表中单词的总数。与单向搜索相同的是,找到所有的变换需要 $M \times N$ 次操作。但是搜索时间会被缩小一半,因为两个搜索会在中间某处相遇。
算法:
算法与之前描述的标准广搜方法相类似。
唯一的不同是我们从两个节点同时开始搜索,同时搜索的结束条件也有所变化。
我们现在有两个访问数组,分别记录从对应的起点是否已经访问了该节点。
如果我们发现一个节点被两个搜索同时访问,就结束搜索过程。因为我们找到了双向搜索的交点。过程如同从中间相遇而不是沿着搜索路径一直走。
双向搜索的结束条件是找到一个单词被两边搜索都访问过了。
- 最短变换序列的长度就是中间节点在两边的层次之和。因此,我们可以在访问数组中记录节点的层次。
int dbfs(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> dict(wordList.begin(), wordList.end());
if (dict.find(beginWord) != dict.end()) return 0;
//初始化
unordered_set<string> beginSet, endSet, tmp, visited;
beginSet.insert(beginWord);
endSet.insert(endWord);
int len = 1;
while (!beginSet.empty() && !endSet.empty()) {
if (beginSet.size() > endSet.size()) {
tmp = beginSet;
beginSet = endSet;
endSet = tmp;
}
tmp.clear();
for (string word : beginSet) {
for (int i = 0; i < word.size(); ++ i) {
char old = word[i];
for (char a = 'a'; a < 'z'; ++ a) {
if (old == a) continue;
word[i] = a;
if (endSet.find(word) != endSet.end()) {
return len + 1;
}
if (visited.find(word) == visited.end() && dict.find(word) != dict.end()) {
tmp.insert(word);
visited.insert(word);
}
}
word[i] = old;
}
}
beginSet = tmp;
++ len;
}
return 0;
}补充
关于set与unordered_set
- set函数(集合):这里的set表示集合的意思,和数学中的集合是一个意思,集合中不允许有重复出现的元素,由于set函数底层通常以红黑树实现,红黑树具有自动排序的功能,因此set内部所有的数据,在任何时候,都是有序的。
- unordered_set函数: 是含有 Key 类型唯一对象集合的关联容器,依赖于哈希表。搜索、插入和移除拥有平均常数时间复杂度。在内部,元素并不以任何特别顺序排序,而是组织进桶中,元素被放进哪个桶完全依赖其值的哈希。允许对单独元素的快速访问,因为一旦哈希,就能够准确指代元素被放入的桶。不可修改容器元素(即使通过非 const 迭代器),因为修改可能更改元素的哈希,并破坏容器。代价是消耗比较多的内存,无自动排序功能。底层实现上,使用一个下标范围比较大的数组来存储元素,形成很多的桶,利用hash函数对key进行映射到不同区域进行保存。
下面几种情况一般使用set:
- 需要有序的数据(元素不同)。
- 需要按顺序打印/访问数据。
- 需要元素的前任或后继。
下面几种情况一般使用unordered_set:
- 需要保留一组不同的元素,不需要排序。
- 需要访问单个元素,不要遍历。
关于map与unordered_map
- map函数(映射): map函数在缺省下,按照递增的排序顺序,并且内部采用了自平衡的BST(二叉搜索树)的数据结构,实现了数据排序。所以在搜索的时候时间复杂度为$Olog(n)$
- unordered_map函数:unordered_map函数不进行排序二内部采用了哈希表的数据结构在搜索的时候时间复杂度为$O(1)$,但是在特殊情况下时间复杂度就会退化为$O(n)$
因此如果你想要一个具有排序后的数据的话,通常可以选择map这种类型。或者想要打印具有一定顺序的元素。如果你只想记录数据而不是想要将数据进行排序的话,那么就可以选择unordered_map这种数据结构。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!